
Arquitectura de aplicaciones para Kubernetes
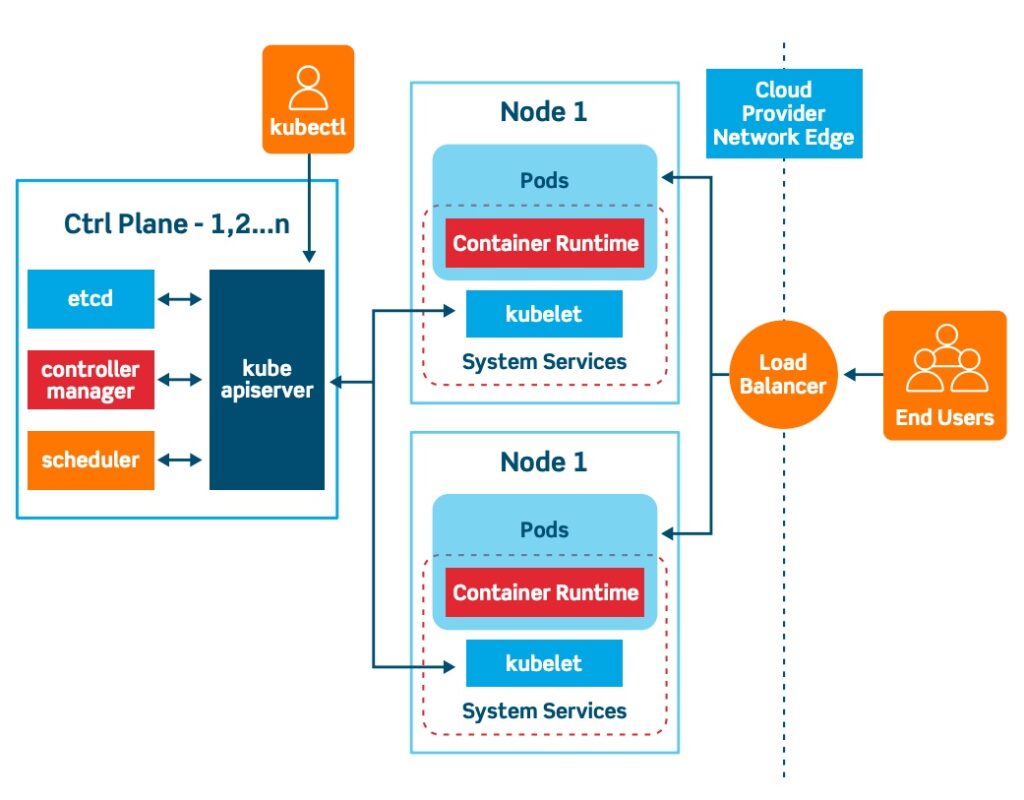
Introducción
Diseñar y ejecutar aplicaciones teniendo en cuenta la escalabilidad, la portabilidad y la solidez puede ser un desafío, especialmente a medida que aumenta la complejidad del sistema. La arquitectura de una aplicación o un sistema dicta cómo debe ejecutarse, qué espera de su entorno y qué tan estrechamente acoplado está con los componentes relacionados. Seguir ciertos patrones durante la fase de diseño y adherirse a ciertas prácticas operativas puede ayudar a contrarrestar algunos de los problemas más comunes que enfrentan las aplicaciones cuando se ejecutan en entornos altamente distribuidos.
Tecnologías como Docker y Kubernetes ayudan a los equipos a empaquetar software y luego distribuirlo, implementarlo y escalarlo en plataformas de computadoras distribuidas. Aprender a aprovechar al máximo el poder de estas herramientas puede ayudarlo a administrar aplicaciones con mayor flexibilidad, control y capacidad de respuesta.
En esta guía, analizaremos algunos de los principios y patrones que puede adoptar para escalar y administrar sus cargas de trabajo en Kubernetes. Si bien Kubernetes puede ejecutar muchos tipos de cargas de trabajo, sus decisiones pueden afectar la facilidad de operación y las posibilidades disponibles.
Si está buscando un servicio de alojamiento de Kubernetes administrado, consulte nuestro servicio de Kubernetes simple y administrado diseñado para el crecimiento .
Diseño para la escalabilidad de aplicaciones
Al producir software, muchos requisitos afectan los patrones y la arquitectura que se eligen emplear. Con Kubernetes, uno de los factores más importantes es la capacidad de escalar horizontalmente , aumentando la cantidad de copias idénticas de su aplicación que se ejecutan en paralelo para distribuir la carga y aumentar la disponibilidad. Esta es una alternativa al escalamiento vertical , que generalmente se refiere al aumento de la capacidad de una sola pila de aplicaciones.
En particular, los microservicios son un patrón de diseño de software que funciona bien para implementaciones escalables en clústeres. Los desarrolladores crean aplicaciones pequeñas y componibles que se comunican a través de la red mediante API bien definidas en lugar de programas compuestos más grandes que se comunican a través de mecanismos internos. La refactorización de aplicaciones monolíticas en componentes discretos de un solo propósito permite escalar cada función de forma independiente. Gran parte de la complejidad y la sobrecarga que normalmente existirían en el nivel de la aplicación se transfieren al ámbito operativo, donde pueden ser administradas por plataformas como Kubernetes.
Más allá de los patrones de software específicos, las aplicaciones nativas de la nube se diseñan teniendo en cuenta algunas consideraciones adicionales. Las aplicaciones nativas de la nube son programas que generalmente siguen un patrón de arquitectura de microservicios con resiliencia, observabilidad y funciones administrativas integradas para aprovechar al máximo las plataformas de la nube.
Por ejemplo, las aplicaciones nativas de la nube se construyen con métricas de informes de estado para permitir que la plataforma administre los eventos del ciclo de vida si una instancia deja de funcionar correctamente. Producen (y ponen a disposición para la exportación) datos de telemetría sólidos para alertar a los operadores sobre problemas y permitirles tomar decisiones informadas. Las aplicaciones están diseñadas para manejar reinicios y fallas regulares, cambios en la disponibilidad del backend y cargas elevadas sin corromper los datos ni dejar de responder.
Siguiendo la filosofía de aplicación de los 12 factores
Una metodología popular que puede ayudarlo a centrarse en las características que más importan al crear aplicaciones web listas para la nube es la filosofía de la aplicación de doce factores . Originalmente escrita para ayudar a los desarrolladores y equipos de operaciones a comprender las cualidades principales que comparten los servicios web diseñados para ejecutarse en la nube, los principios se aplican muy bien al software que vivirá en un entorno agrupado como Kubernetes. Si bien las aplicaciones monolíticas pueden beneficiarse de seguir estas recomendaciones, las arquitecturas de microservicios diseñadas en torno a estos principios funcionan particularmente bien.
Un resumen rápido de los Doce Factores son:
- Base de código: administra todo el código en sistemas de control de versiones (como Git o Mercurial). La base de código dicta de manera integral lo que se implementa.
- Dependencias: Las dependencias deben ser administradas en su totalidad y de manera explícita por el código base, ya sea proporcionado por el proveedor (almacenado con el código) o fijado en una versión en un formato desde el cual un administrador de paquetes pueda instalar.
- Configuración: separe los parámetros de configuración de la aplicación y defínalos en el entorno de implementación en lugar de integrarlos en la aplicación misma.
- Servicios de respaldo: Tanto los servicios locales como los remotos se abstraen como recursos accesibles a través de la red con detalles de conexión establecidos en la configuración.
- Compilar, lanzar, ejecutar: la etapa de compilación de su aplicación debe estar completamente separada de los procesos de lanzamiento y operaciones de la aplicación. La etapa de compilación crea un artefacto de implementación a partir del código fuente, la etapa de lanzamiento combina el artefacto y la configuración, y la etapa de ejecución ejecuta el lanzamiento.
- Procesos: Las aplicaciones se implementan como procesos que no deben depender del almacenamiento local del estado. El estado debe transferirse a un servicio de respaldo, como se describe en el cuarto factor.
- Vinculación de puertos: las aplicaciones deben vincularse de forma nativa a un puerto y escuchar las conexiones. El enrutamiento y el reenvío de solicitudes deben gestionarse de forma externa.
- Simultaneidad: las aplicaciones deben basarse en la escalabilidad a través del modelo de proceso. Ejecutar varias copias de una aplicación simultáneamente, posiblemente en varios servidores, permite la escalabilidad sin ajustar el código de la aplicación.
- Desechabilidad: Los procesos deben poder iniciarse rápidamente y detenerse sin problemas y sin efectos secundarios graves.
- Paridad entre desarrollo y producción: los entornos de prueba, ensayo y producción deben coincidir estrechamente y mantenerse sincronizados. Las diferencias entre entornos son oportunidades para que aparezcan incompatibilidades y configuraciones no probadas.
- Registros: las aplicaciones deben transmitir registros a la salida estándar para que los servicios externos puedan decidir cómo manejarlos mejor.
- Procesos de administración: Los procesos de administración únicos deben ejecutarse en versiones específicas y enviarse con el código del proceso principal.
Si sigue las pautas proporcionadas por los Doce Factores, podrá crear y ejecutar aplicaciones que se adapten bien a Kubernetes. Los Doce Factores alientan a los desarrolladores a centrarse en el propósito principal de su aplicación, considerar las condiciones operativas y las interfaces entre los componentes, y usar entradas, salidas y funciones de administración de procesos estándar para ejecutarse de manera predecible en Kubernetes.
Componentes de aplicaciones en contenedores
Kubernetes utiliza contenedores para ejecutar aplicaciones aisladas y empaquetadas en los nodos de su clúster. Para ejecutarse en Kubernetes, sus aplicaciones deben estar encapsuladas en una o más imágenes de contenedor y ejecutarse mediante un entorno de ejecución de contenedor como Docker. Si bien la contenedorización de sus componentes es un requisito para Kubernetes, también ayuda a reforzar muchos de los principios de la metodología de aplicaciones de doce factores que se mencionó anteriormente, lo que permite una mejor escalabilidad y administración.
Por ejemplo, los contenedores proporcionan aislamiento entre el entorno de la aplicación y el sistema host externo. Admiten un enfoque en red para la comunicación entre aplicaciones y, por lo general, toman la configuración a través de variables ambientales y exponen registros escritos en stdouty stderr. Los contenedores en sí mismos fomentan la concurrencia basada en procesos y ayudan a mantener la paridad de desarrollo/producción al ser escalables de forma independiente y agrupar el entorno de ejecución del proceso. Estas características permiten empaquetar sus aplicaciones para que se ejecuten sin problemas en Kubernetes.
Directrices para optimizar los contenedores
La flexibilidad de la tecnología de contenedores permite muchas formas distintas de encapsular una aplicación. Sin embargo, algunos métodos funcionan mejor en un entorno de Kubernetes que otros.
La mayoría de las mejores prácticas para contenerizar sus aplicaciones tienen que ver con la creación de imágenes, donde usted define cómo se configurará y ejecutará su software desde dentro de un contenedor. En general, mantener los tamaños de las imágenes pequeños y sencillos ofrece una serie de beneficios. Las imágenes optimizadas en cuanto al tamaño pueden reducir el tiempo y los recursos necesarios para iniciar un nuevo contenedor en un clúster al reutilizar las capas existentes entre actualizaciones de imágenes, algo que Docker y otros marcos de contenedores están diseñados para hacer automáticamente.
Un buen primer paso al crear imágenes de contenedores es hacer todo lo posible para separar los pasos de compilación de la imagen final que se ejecutará en producción. Compilar o agrupar software generalmente requiere herramientas adicionales, lleva más tiempo y produce artefactos (por ejemplo, dependencias multiplataforma) que pueden ser inconsistentes de un contenedor a otro o innecesarios para el entorno de ejecución final. Una forma de separar claramente el proceso de compilación del entorno de ejecución es usar compilaciones de varias etapas de Docker . Las configuraciones de compilación de varias etapas le permiten especificar una imagen base para usar durante su proceso de compilación y definir otra para usar en el tiempo de ejecución. Esto hace posible compilar software usando una imagen con todas las herramientas de compilación instaladas y copiar los artefactos resultantes a una imagen delgada y optimizada que se usará cada vez después.
Con este tipo de funcionalidad disponible, suele ser una buena idea crear imágenes de producción sobre una imagen principal mínima. Si desea evitar por completo la hinchazón que se encuentra en las capas principales de estilo “distribución” como ubuntu:20.04(que incluye un entorno de servidor Ubuntu 20.04 completo), puede crear sus imágenes con scratch— la imagen base más mínima de Docker — como la principal. Sin embargo, la scratchcapa base no proporciona acceso a muchas herramientas básicas y, a menudo, romperá algunas suposiciones básicas sobre un entorno Linux. Como alternativa, la imagen Alpine Linux alpine se ha vuelto popular por ser un entorno base sólido y mínimo que proporciona una distribución Linux pequeña, pero con todas las funciones.
En el caso de los lenguajes interpretados, como Python o Ruby, el paradigma cambia ligeramente, ya que no existe una etapa de compilación y el intérprete debe estar disponible para ejecutar el código en producción. Sin embargo, dado que las imágenes delgadas siguen siendo ideales, en Docker Hub hay disponibles muchas imágenes optimizadas y específicas para cada lenguaje creadas sobre Alpine Linux . Los beneficios de usar una imagen más pequeña para los lenguajes interpretados son similares a los de los lenguajes compilados: Kubernetes podrá extraer rápidamente todas las imágenes de contenedor necesarias en nuevos nodos para comenzar a realizar un trabajo significativo.
Decidir el alcance de los contenedores y los pods
Si bien sus aplicaciones deben estar en contenedores para ejecutarse en un clúster de Kubernetes, los pods son la unidad de abstracción más pequeña que Kubernetes puede administrar directamente. Un pod es un objeto de Kubernetes compuesto por uno o más contenedores estrechamente acoplados. Los contenedores de un pod comparten un ciclo de vida y se administran juntos como una sola unidad. Por ejemplo, los contenedores siempre se programan (implementan) en el mismo nodo (servidor), se inician o detienen al unísono y comparten recursos como sistemas de archivos y direcciones IP.
Es importante comprender cómo maneja Kubernetes estos componentes y qué proporciona cada capa de abstracción a sus sistemas. Algunas consideraciones pueden ayudarlo a identificar algunos puntos naturales de encapsulación para su aplicación con cada una de estas abstracciones.
Una forma de determinar un alcance efectivo para sus contenedores es buscar límites de desarrollo naturales. Si sus sistemas operan con una arquitectura de microservicios, los contenedores bien diseñados se crean con frecuencia para representar unidades discretas de funcionalidad que a menudo se pueden usar en una variedad de contextos. Este nivel de abstracción le permite a su equipo publicar cambios en imágenes de contenedores y luego implementar esta nueva funcionalidad en cualquier entorno donde se utilicen esas imágenes. Las aplicaciones se pueden crear componiendo contenedores individuales que cumplan cada uno una función determinada, pero que quizás no logren un proceso completo por sí solos.
A diferencia de lo anterior, los pods se construyen generalmente pensando en qué partes de su sistema podrían beneficiarse más de la administración independiente . Dado que Kubernetes usa pods como su abstracción más pequeña orientada al usuario, estas son las unidades más primitivas con las que las herramientas y la API de Kubernetes pueden interactuar y controlar directamente. Puede iniciar, detener y reiniciar pods, o usar objetos de nivel superior creados sobre pods para introducir funciones de replicación y administración del ciclo de vida. Kubernetes no le permite administrar los contenedores dentro de un pod de forma independiente, por lo que no debe agrupar contenedores que podrían beneficiarse de una administración separada.
Dado que muchas de las características y abstracciones de Kubernetes se relacionan directamente con los pods, tiene sentido agrupar los elementos que deben escalarse juntos en un solo pod y separar aquellos que deben escalar de forma independiente. Por ejemplo, separar los servidores web de los servidores de aplicaciones en diferentes pods le permite escalar cada capa de forma independiente según sea necesario. Sin embargo, agrupar un servidor web y un adaptador de base de datos en el mismo pod puede tener sentido si el adaptador proporciona la funcionalidad esencial que el servidor web necesita para funcionar correctamente.
Mejora de la funcionalidad de los pods mediante la agrupación de contenedores de apoyo
Teniendo esto en mente, ¿qué tipos de contenedores se deben agrupar en un solo pod? Generalmente, un contenedor principal es responsable de cumplir con las funciones principales del pod, pero se pueden definir contenedores adicionales que modifiquen o amplíen el contenedor principal o lo ayuden a conectarse a un entorno de implementación único.
Por ejemplo, en un pod de servidor web, un contenedor Nginx puede escuchar solicitudes y entregar contenido mientras un contenedor asociado actualiza archivos estáticos cuando cambia un repositorio. Puede resultar tentador empaquetar ambos componentes dentro de un solo contenedor, pero implementarlos como contenedores separados tiene importantes beneficios. Tanto el contenedor de servidor web como el extractor de repositorios se pueden usar de forma independiente en diferentes contextos. Pueden ser mantenidos por diferentes equipos y cada uno puede desarrollarse para generalizar su comportamiento y trabajar con diferentes contenedores complementarios.
Brendan Burns y David Oppenheimer identificaron tres patrones principales para agrupar contenedores de soporte en su artículo sobre patrones de diseño para sistemas distribuidos basados en contenedores . Estos representan algunos de los casos de uso más comunes para agrupar contenedores en un pod:
- Sidecar: en este patrón, el contenedor secundario amplía y mejora la funcionalidad principal del contenedor principal. Este patrón implica ejecutar funciones no estándar o de utilidad en un contenedor independiente. Por ejemplo, un contenedor que reenvía registros o vigila valores de configuración actualizados puede aumentar la funcionalidad de un pod sin cambiar su enfoque principal.
- Embajador: el patrón embajador utiliza un contenedor complementario para abstraer recursos remotos para el contenedor principal. El contenedor principal se conecta directamente al contenedor embajador, que a su vez se conecta y abstrae grupos de recursos externos potencialmente complejos, como un clúster distribuido de Redis. El contenedor principal no tiene que conocer ni preocuparse por el entorno de implementación real para conectarse a servicios externos.
- Adaptador: el patrón adaptador se utiliza para traducir los datos, protocolos o interfaces del contenedor principal para que se ajusten a los estándares esperados por terceros. Los contenedores adaptadores permiten un acceso uniforme a servicios centralizados incluso cuando las aplicaciones a las que sirven solo admitan de forma nativa interfaces incompatibles.
Extracción de la configuración en ConfigMaps y Secrets
Si bien la configuración de la aplicación se puede integrar en imágenes de contenedores, es mejor hacer que los componentes se puedan configurar en tiempo de ejecución para admitir la implementación en múltiples contextos y permitir una administración más flexible. Para administrar los parámetros de configuración en tiempo de ejecución, Kubernetes ofrece dos tipos diferentes de objetos, denominados ConfigMaps y Secrets .
Los ConfigMaps son un mecanismo que se utiliza para almacenar datos que se pueden exponer a pods y otros objetos en tiempo de ejecución. Los datos almacenados en ConfigMaps se pueden presentar como variables de entorno o montar como archivos en el pod. Al diseñar sus aplicaciones para que lean desde estas ubicaciones, puede inyectar la configuración en tiempo de ejecución mediante ConfigMaps y modificar el comportamiento de sus componentes sin tener que reconstruir la imagen del contenedor.
Los secretos son un tipo de objeto similar de Kubernetes que se utiliza para almacenar de forma segura datos confidenciales y permitir de forma selectiva que los pods y otros componentes accedan a ellos según sea necesario. Los secretos son una forma conveniente de pasar material confidencial a las aplicaciones sin almacenarlos como texto sin formato en ubicaciones de fácil acceso en su configuración normal. Funcionalmente, funcionan de la misma manera que los ConfigMaps, por lo que las aplicaciones pueden consumir datos de ConfigMaps y Secrets utilizando los mismos mecanismos.
Los ConfigMaps y Secrets le ayudan a evitar colocar parámetros de configuración directamente en las definiciones de objetos de Kubernetes. Puede asignar la clave de configuración en lugar del valor, lo que le permite actualizar la configuración sobre la marcha modificando el ConfigMap o Secret. Esto le brinda la oportunidad de alterar el comportamiento de tiempo de ejecución activo de los pods y otros objetos de Kubernetes sin modificar las definiciones de Kubernetes de los recursos.
Implementación de sondas de preparación y actividad
Kubernetes incluye muchas funciones listas para usar para administrar los ciclos de vida de los componentes y garantizar que sus aplicaciones siempre estén en buen estado y disponibles. Sin embargo, para aprovechar estas funciones, Kubernetes debe comprender cómo debe monitorear e interpretar el estado de su aplicación. Para ello, Kubernetes le permite definir sondas de actividad y preparación .
Las sondas de actividad permiten a Kubernetes determinar si una aplicación dentro de un contenedor está activa y ejecutándose de forma activa. Kubernetes puede ejecutar comandos periódicamente dentro del contenedor para verificar el comportamiento básico de la aplicación o puede enviar solicitudes de red HTTP o TCP a una ubicación designada para determinar si el proceso está disponible y puede responder como se espera. Si una sonda de actividad falla, Kubernetes reinicia el contenedor para intentar restablecer la funcionalidad dentro del pod.
Las sondas de preparación son una herramienta similar que se utiliza para determinar si un pod está listo para atender el tráfico. Es posible que las aplicaciones dentro de un contenedor deban realizar procedimientos de inicialización antes de estar listas para aceptar solicitudes de clientes o que deban volver a cargarse tras un cambio de configuración. Cuando falla una sonda de preparación, en lugar de reiniciar el contenedor, Kubernetes deja de enviar solicitudes al pod temporalmente. Esto permite que el pod complete sus rutinas de inicialización o mantenimiento sin afectar el estado del grupo en su conjunto.
Al combinar sondas de actividad y preparación, puede indicarle a Kubernetes que reinicie automáticamente los pods o los elimine de los grupos de backend. Configurar su infraestructura para aprovechar estas capacidades le permite a Kubernetes administrar la disponibilidad y el estado de sus aplicaciones sin trabajo de operaciones adicional.
Uso de implementaciones para gestionar la escala y la disponibilidad
Anteriormente, cuando analizamos algunos aspectos básicos del diseño de pods, mencionamos que otros objetos de Kubernetes se basan en estos primitivos para proporcionar una funcionalidad más avanzada. Una implementación , uno de esos objetos compuestos, es probablemente el objeto de Kubernetes más comúnmente definido y manipulado.
Las implementaciones son objetos compuestos que se basan en otras primitivas de Kubernetes para agregar capacidades adicionales. Agregan capacidades de administración del ciclo de vida a objetos intermedios llamados ReplicaSets , como la capacidad de realizar actualizaciones continuas, revertir a versiones anteriores y realizar transiciones entre estados. Estos ReplicaSets le permiten definir plantillas de pod para crear y administrar varias copias de un único diseño de pod. Esto lo ayuda a escalar fácilmente su infraestructura, administrar los requisitos de disponibilidad y reiniciar automáticamente los pods en caso de falla.
Estas características adicionales proporcionan un marco administrativo y capacidades de autorreparación a la capa base de pods. Si bien los pods son las unidades que, en última instancia, ejecutan las cargas de trabajo que usted define, no son las unidades que debería aprovisionar y administrar normalmente. En cambio, piense en los pods como un bloque de construcción que puede ejecutar aplicaciones de manera sólida cuando se aprovisionan a través de objetos de nivel superior, como las implementaciones.
Creación de servicios y reglas de ingreso para gestionar el acceso a las capas de la aplicación
Las implementaciones le permiten aprovisionar y administrar conjuntos de pods intercambiables para escalar sus aplicaciones y satisfacer las demandas de los usuarios. Sin embargo, el enrutamiento del tráfico a los pods aprovisionados es una preocupación aparte. A medida que los pods se intercambian como parte de las actualizaciones continuas, se reinician o se mueven debido a fallas del host, las direcciones de red asociadas anteriormente con el grupo en ejecución cambiarán. Los servicios de Kubernetes le permiten administrar esta complejidad al mantener la información de enrutamiento para grupos dinámicos de pods y controlar el acceso a varias capas de su infraestructura.
En Kubernetes, los servicios son mecanismos específicos que controlan cómo se enruta el tráfico a los conjuntos de pods. Ya sea que se reenvíe el tráfico desde clientes externos o se administren las conexiones entre varios componentes internos, los servicios le permiten controlar cómo debe fluir el tráfico. Kubernetes luego actualizará y mantendrá toda la información necesaria para reenviar las conexiones a los pods relevantes, incluso cuando el entorno cambie y se modifique el direccionamiento de la red.
Acceso a servicios internos
Para utilizar los servicios de manera eficaz, primero debe determinar los consumidores previstos para cada grupo de pods. Si su servicio solo lo utilizarán otras aplicaciones implementadas dentro de su clúster de Kubernetes, el tipo de servicio clusterIP le permite conectarse a un conjunto de pods mediante una dirección IP estable que solo se puede enrutar desde dentro del clúster. Cualquier objeto implementado en el clúster puede comunicarse con el grupo de pods replicados enviando tráfico directamente a la dirección IP del servicio. Este es el tipo de servicio más sencillo, que funciona bien para las capas de aplicaciones internas.
Un complemento DNS opcional permite que Kubernetes proporcione nombres DNS para los servicios. Esto permite que los pods y otros objetos se comuniquen con los servicios por nombre en lugar de por dirección IP. Este mecanismo no cambia significativamente el uso del servicio, pero los identificadores basados en nombres pueden simplificar la conexión de componentes o la definición de interacciones sin conocer necesariamente la dirección IP del servicio.
Exponiendo servicios al consumo público
Si la interfaz debe ser de acceso público, la mejor opción suele ser el tipo de servicio de balanceador de carga . Este utiliza la API de su proveedor de nube específico para aprovisionar un balanceador de carga, que envía tráfico a los pods de servicio a través de una dirección IP expuesta públicamente. Esto le permite enrutar solicitudes externas a los pods de su servicio, lo que ofrece un canal de red controlado a su red de clúster interna.
Dado que el tipo de servicio de balanceador de carga crea un balanceador de carga para cada servicio, puede resultar costoso exponer los servicios de Kubernetes públicamente mediante este método. Para ayudar a aliviar esto, se pueden usar objetos de ingreso de Kubernetes para describir cómo enrutar diferentes tipos de solicitudes a diferentes servicios según un conjunto predeterminado de reglas. Por ejemplo, las solicitudes de “ ejemplo.com ” pueden ir al servicio A, mientras que las solicitudes de “ sammytheshark.com ” pueden enrutarse al servicio B. Los objetos de ingreso proporcionan una forma de describir cómo enrutar de manera lógica un flujo mixto de solicitudes a sus servicios de destino según patrones predefinidos.
Las reglas de ingreso deben ser interpretadas por un controlador de ingreso (normalmente algún tipo de equilibrador de carga, como Nginx) implementado dentro del clúster como un pod, que implementa las reglas de ingreso y reenvía el tráfico a los servicios de Kubernetes en consecuencia. Las implementaciones de ingreso se pueden utilizar para minimizar la cantidad de equilibradores de carga externos que los propietarios del clúster deben ejecutar.
Uso de sintaxis declarativa para gestionar el estado de Kubernetes
Kubernetes ofrece mucha flexibilidad para definir y controlar los recursos implementados en su clúster. Con herramientas como kubectl, puede definir de manera imperativa objetos ad hoc para implementarlos inmediatamente en su clúster. Si bien esto puede ser útil para implementar recursos rápidamente al aprender Kubernetes, este enfoque tiene desventajas que lo hacen indeseable para la administración de producción a largo plazo.
Uno de los principales problemas de la gestión imperativa es que no deja ningún registro de los cambios que se han implementado en el clúster. Esto hace que sea difícil o imposible recuperarse en caso de fallos o realizar un seguimiento de los cambios operativos a medida que se aplican a los sistemas.
Afortunadamente, Kubernetes ofrece una sintaxis declarativa alternativa que le permite definir completamente los recursos dentro de archivos de texto y luego usarlos kubectlpara aplicar la configuración o el cambio. Almacenar estos archivos de configuración en un repositorio de control de versiones es una buena manera de monitorear los cambios e integrarlos con los procesos de revisión utilizados para otras partes de su organización. La administración basada en archivos también permite adaptar los patrones existentes a los nuevos recursos mediante la copia y edición de las definiciones existentes. Almacenar las definiciones de objetos de Kubernetes en directorios con versiones le permite mantener una instantánea del estado deseado del clúster en cada momento. Esto puede resultar invaluable durante las operaciones de recuperación, las migraciones o al rastrear la causa raíz de los cambios no deseados introducidos en su sistema.
Conclusión
Administrar la infraestructura que ejecutará sus aplicaciones y aprender a aprovechar al máximo las características que ofrecen los entornos de orquestación modernos puede resultar abrumador. Sin embargo, muchos de los beneficios que ofrecen sistemas como Kubernetes y tecnologías como los contenedores se vuelven más claros cuando sus prácticas de desarrollo y operaciones se alinean con los conceptos en los que se basa la herramienta. Diseñar sus sistemas utilizando los patrones en los que Kubernetes se destaca y comprender cómo ciertas características pueden aliviar los desafíos de las implementaciones complejas puede mejorar su experiencia al ejecutar en la plataforma.
A continuación, es posible que desees leer sobre cómo modernizar aplicaciones existentes para Kubernetes .
Deja una respuesta